서문
최근 JPEG 인코딩 방법을 배우면서 인터넷에서 많은 글을 찾아보았지만, 모든 세부 사항을 명확하게 설명하는 글은 거의 없어 프로그래밍할 때 많은 함정에 빠졌습니다. 그래서 가능한 한 Python 코드와 함께 세부 사항을 다루는 글을 작성하려고 합니다. 구체적인 프로그램은 제 Github 오픈 소스 프로젝트를 참고하세요.

물론, 이 소개와 코드는 완벽하지 않으며 심지어 오류가 있을 수도 있습니다. 단지 입문 가이드로만 봐주시길 바랍니다.
JPEG 파일의 다양한 마커
많은 글에서 JPEG 파일의 마커를 소개하고 있습니다. 저도 실제 이미지에 주석을 단 문서(다운로드 클릭)를 업로드했으니 참고하세요.
모든 마커는 0xff(16진수 255)로 시작하며, 그 뒤에 이 블록의 데이터 바이트 수와 블록 정보를 설명하는 데이터가 따릅니다. 구체적인 내용은 아래 그림과 같습니다:
CodeBlock Loading...
여기까지 이미지 데이터 부분만 작성하지 않았습니다. 하지만 이미지 데이터 부분이 어떻게 인코딩되는지, 그리고 위에서 언급한 양자화, 허프만 인코딩이 구체적으로 어떻게 구현되는지는 다음 부분의 소개를 참고하세요.
JPEG 인코딩 과정
JPEG 인코딩 과정에서는 이미지를 8*8 블록으로 나누어야 하므로, 이미지의 높이와 너비가 모두 8의 배수여야 합니다. 따라서 이미지 보간 또는 샘플링 방법을 사용하여 이미지를 약간 변경하여 높이와 너비가 모두 8의 배수가 되도록 만들 수 있습니다. 수천 개의 픽셀로 이루어진 이미지의 경우, 이 작업은 이미지의 전체 종횡비에 큰 변화를 주지 않습니다.
CodeBlock Loading...
색 공간 변환
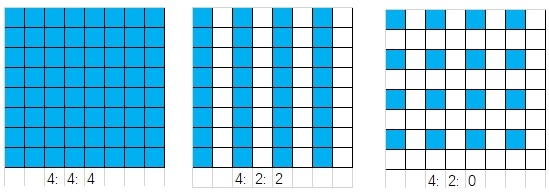
JPEG 이미지는 통일적으로 YCbCr 색 공간을 사용합니다. 이는 사람의 눈이 밝기에는 민감하지만 색차에는 덜 민감하기 때문입니다. 따라서 Cb와 Cr 성분의 압축을 선택적으로 늘려 이미지의 시각적 품질을 유지하면서 이미지 크기를 더 크게 줄일 수 있습니다. YCbCr 공간으로 변환한 후, Cb Cr 색상 성분을 샘플링하여 포인트 수를 줄여 더 높은 압축률을 달성할 수 있습니다. 일반적인 샘플링 형식으로는 4:4:4, 4:2:2, 4:2:0이 있습니다. 여기서 SOF0 마커의 수평 샘플링 팩터와 수직 샘플링 팩터가 이에 해당합니다. 간단하게 하기 위해, 본문에서는 모든 샘플링 팩터를 1로, 즉 샘플링을 하지 않고 하나의 Y 성분이 하나의 Cb Cr 성분에 대응합니다(4:4:4). 4:2:2는 두 개의 Y 성분이 하나의 Cb Cr 성분에 대응하고, 4:2:0은 네 개의 Y 성분이 하나의 Cb Cr 성분에 대응합니다. 아래 그림에서 각 셀은 하나의 Y 성분에 해당하고, 파란색 칸은 Cb Cr 성분이 샘플링된 픽셀입니다.
색 공간 변환 공식은 다음과 같습니다:
위 연산은 모두 반올림하여 정수로 만듭니다. 24비트 RGB bmp 이미지에서 R G B 성분의 범위는 모두 0-255이며, 간단한 수학적 관계를 통해 Y Cb Cr 성분의 범위도 0-255임을 쉽게 알 수 있습니다. JPEG 이미지에서는 일반적으로 각 성분에서 128을 빼서 범위가 양수와 음수를 모두 가지도록 합니다.
Python에서는 opencv 라이브러리의 함수를 사용하여 색 공간 변환을 수행할 수 있습니다:
CodeBlock Loading...
8*8 블록 분할
JPEG 인코딩에서는 각 8*8 블록을 처리하며, 위에서 아래로, 왼쪽에서 오른쪽으로 순서대로 데이터 처리를 진행하고, 마지막에 각 블록의 데이터를 합치면 됩니다. 각 블록의 Y Cb Cr 세 가지 색상 성분에 대해 Y Cb Cr 순서로 동일한 작업을 수행합니다(사용하는 양자화 테이블과 허프만 테이블은 다를 수 있습니다).
CodeBlock Loading...
DCT 변환
DCT(이산 코사인 변환)는 공간 영역의 데이터를 주파수 영역으로 변환하여 연산합니다. 이를 통해 주파수 영역에서 선택적으로 고주파 성분의 데이터를 줄일 수 있으며, 이미지의 시각적 품질에 큰 영향을 주지 않습니다. 이산 푸리에 변환에 비해 이산 코사인 변환은 모두 실수 영역에서 연산되므로 컴퓨터 연산에 더 유리합니다. 이산 코사인 변환의 공식은 다음과 같습니다:
여기서 입니다. JPEG에서는 입니다.
물론 opencv 라이브러리의 함수를 사용할 수도 있습니다:
CodeBlock Loading...
양자화
DCT 변환 후, 직류 성분은 88 블록의 첫 번째 요소이며, 저주파 성분은 왼쪽 위 모서리에 집중되고, 고주파 성분은 오른쪽 아래 모서리에 집중됩니다. 선택적으로 고주파 성분을 제거하기 위해 양자화 작업을 수행할 수 있습니다. 실제로는 88 블록의 각 요소를 고정된 값으로 나누는 것입니다. 양자화 테이블에서 왼쪽 위의 요소는 작고 오른쪽 아래는 큽니다. 양자화 테이블의 예는 다음과 같습니다(Y 성분과 Cb Cr 성분은 서로 다른 양자화 테이블을 사용합니다):
CodeBlock Loading...
양자화 과정 코드:
CodeBlock Loading...
양자화 후, 8*8 블록의 오른쪽 아래 모서리에 많은 0이 나타납니다. 이러한 0을 집중시켜 런 렝스 인코딩에서 더 적은 데이터 양을 얻기 위해, 다음으로 zigzag 스캔을 수행합니다.
zigzag 스캔
소위 zigzag 스캔은 실제로 8*8 블록을 다음 순서에 따라 64개 항목의 리스트로 변환하는 것입니다.
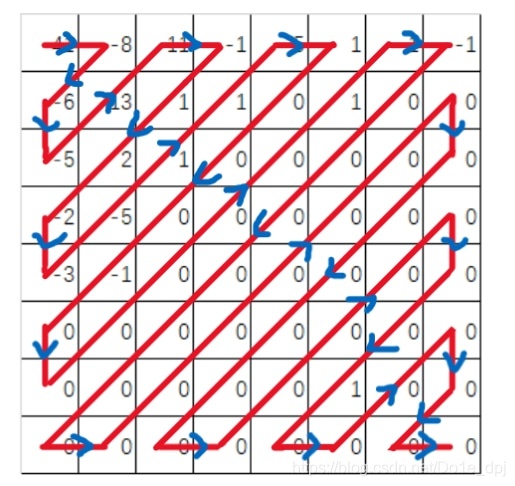
최종적으로 다음과 같은 길이 64의 리스트를 얻습니다: (41, -8, -6, -5, 13, 11, -1, 1, 2, -2, -3, -5, 1, 1, -5, 1, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 1, 1, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0). 이후의 작업은 모두 이 리스트를 예로 들어 설명합니다.
주의할 점은, 양자화 테이블을 저장할 때도 해당 테이블을 zigzag 스캔하여 이 형식으로 저장해야 이미지 뷰어가 올바른 이미지를 디코딩할 수 있다는 것입니다(저는 처음에 이 세부 사항에서 많은 디버깅 시간을 소비했습니다). 본문 시작 부분의 마커 작성 코드를 참고하세요.
CodeBlock Loading...
차분 인코딩 (직류 성분)
직류 성분의 값은 종종 크며, 동시에 인접한 8*8 블록의 직류 성분은 서로 매우 유사합니다. 따라서 차분 인코딩을 사용하면 공간을 더 크게 절약할 수 있습니다. 차분 인코딩이란 현재 블록과 이전 블록의 직류 성분 차이를 저장하는 것이며, 첫 번째 블록은 자기 자신을 저장합니다. 주의할 점은, Y Cb Cr 세 성분에 대해 각각 대응하여 차분 인코딩을 수행한다는 것입니다. 즉, 각 성분끼리 뺍니다. 아래에서 직류 성분 nowblockdc를 어떻게 인코딩하고 저장하는지 소개하겠습니다.
CodeBlock Loading...
0의 런 렝스 인코딩 (교류 성분)
zigzag 스캔 후, 많은 0이 함께 모이게 됩니다. 교류 성분의 리스트는 다음과 같습니다: (-8, -6, -5, 13, 11, -1, 1, 2, -2, -3, -5, 1, 1, -5, 1, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 1, 1, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0).
0의 런 렝스 인코딩은 매번 두 개의 숫자를 저장합니다. 두 번째 숫자는 0이 아닌 숫자이고, 첫 번째 숫자는 이 0이 아닌 숫자 앞에 있는 0의 개수입니다. 마지막에는 두 개의 0을 종료 마커로 사용합니다(특히 주의할 점은, 입력 데이터가 0으로 끝나지 않을 때는 두 개의 0을 종료 마커로 사용할 필요가 없다는 것입니다. 이 버그를 찾는 데 오랜 시간이 걸렸습니다. 아래 코드 23행 참조). 위 리스트를 런 렝스 인코딩하면 다음과 같습니다: (0, -8), (0, -6), (0, -5), (0, 13), (0, 11), (0, -1), (0, 1), (0, 2), (0, -2), (0, -3), (0, -5), (0, 1), (0, 1), (0, -5), (0, 1), (3, -1), (6, 1), (0, 1), (0, -1),(27, 1), (0, 0). 이 데이터의 길이는 42로, 원래 63에 비해 약간 줄었습니다. 물론 여기서는 특별한 데이터를 선택했으며, 실제 데이터는 더 많은 0을 포함하거나 심지어 모두 0일 수 있어 인코딩 후 크기가 더 작아질 수 있습니다.
아마도 위 데이터에서 (27, 1)이 빨간색으로 표시된 것을 눈치채셨을 것입니다. 이는 8부의 인코딩에서 첫 번째 숫자가 4비트 숫자로 저장되므로 범위가 0~15이기 때문입니다. 여기서는 분명히 초과되었으므로, 이를 (15, 0), (11, 1)로 분할해야 합니다. 여기서 (15, 0)은 16개의 0을, (11, 1)은 11개의 0 뒤에 1이 있음을 나타냅니다.
CodeBlock Loading...
JPEG 특수 바이너리 인코딩
위의 준비를 마친 후, 이 부분에서는 인코딩된 직류 성분과 교류 성분이 어떻게 데이터 스트림 형태로 파일에 기록되는지 실제로 소개합니다.
JPEG 인코딩에는 다음과 같은 바이너리 인코딩 형식이 있습니다:
CodeBlock Loading...
저장할 숫자에 대해 위 형식에 따라 저장해야 할 비트 길이와 실제 저장할 바이너리 값을 얻어야 합니다. 그 규칙을 관찰하면, 양수의 저장 값은 실제 바이너리이며, 비트 길이도 실제 비트 길이임을 쉽게 알 수 있습니다. 대응하는 음수도 동일한 비트 길이를 가지며, 바이너리 값은 비트 단위로 반전된 값입니다. 0은 저장할 필요가 없습니다.
CodeBlock Loading...
직류 성분의 경우, 차분 인코딩 후의 값이 -41이라고 가정하면, 위 작업을 통해 비트 길이가 6이고 저장할 바이너리 데이터 스트림이 010110임을 얻을 수 있습니다. 데이터 6에 대해서는 표준 허프만 인코딩을 사용하여 바이너리 데이터 스트림을 저장해야 합니다. 이 부분은 9부에서 소개하겠습니다. 먼저 6이 저장된 바이너리 데이터 스트림이 100이라고 가정하면, 이 8*8 블록의 특정 색상 성분의 직류량은 100010110으로 저장됩니다.
직류 성분의 바이너리 데이터 스트림을 파일에 기록한 후, 다음으로 이 8*8 블록의 이 색상 성분의 교류량을 인코딩합니다. 런 렝스 인코딩 후 얻은 값은 다음과 같습니다: (0, -8), (0, -6), (0, -5), (0, 13), (0, 11), (0, -1), (0, 1), (0, 2), (0, -2), (0, -3), (0, -5), (0, 1), (0, 1), (0, -5), (0, 1), (3, -1), (6, 1), (0, 1), (0, -1),(15, 0), (11, 1) , (0, 0).
먼저 (0, -8)을 저장합니다. 두 번째 숫자에 대해 동일한 작업을 수행하여 4비트와 0111을 얻습니다. 그러나 직류 성분과 달리, 0x04에 대해 표준 허프만 인코딩을 수행해야 합니다. 여기서 상위 4비트는 (0, -8)의 첫 번째 숫자이고, 하위 4비트는 두 번째 숫자의 저장 비트 길이입니다. 0x04의 표준 허프만 인코딩 후 저장 값이 1011이라고 가정하면, (0, -8)은 10110111로 저장됩니다. 다음으로 (0, -6) 등에 대해 동일한 작업을 수행하여 얻은 데이터 스트림을 순차적으로 파일에 기록합니다.
또 다른 예로 (6, 1)을 들면, 여기서 1은 1로 저장되며 1비트입니다. 따라서 0x61에 대해 표준 허프만 인코딩을 수행합니다. 가정된 값이 1111011이라면, (6, 1)은 11110111로 저장됩니다. (15, 0)은 0xf0의 표준 허프만 인코딩 값만 저장합니다.
위 과정에 따라 하나의 색상 성분(예: Y)의 데이터를 모두 기록한 후, 다음으로 이 88 블록의 Cb 색상 성분 데이터를 기록하고, 이어서 Cr 성분 데이터를 기록합니다. 동일한 방식으로 왼쪽에서 오른쪽으로, 위에서 아래로 각 88 블록 데이터를 기록한 후, EOI 마커(0xffd9)를 기록하여 이미지 끝을 나타냅니다.
주의: 데이터 기록 과정에서 0xff가 기록되는지 감지해야 합니다. 마커 충돌을 방지하기 위해 뒤에 0x00을 추가해야 합니다.
CodeBlock Loading...
표준 허프만 인코딩
본문에서 소개하는 표준 허프만 인코딩에는 총 4개의 인코딩 테이블이 있으며, 각각 휘도 직류 성분, 색차 직류 성분, 휘도 교류 성분, 색차 교류 성분에 사용됩니다.
CodeBlock Loading...
위 코드에서 stdhuffmanDC0 등은 실제로 마커에 저장되는 값입니다. 자세한 내용은 마커 소개 부분의 코드를 참조하세요. 이 숫자들 중 처음 16개의 숫자(0, 0, 7, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0)는 인코딩 후 길이가 1~16비트인 코드가 각각 몇 개인지 나타내며, 뒤에 이어지는 12개의 숫자는 정확히 처음 16개 숫자의 합입니다. stdhuffmanDC0이 실제로 설명하는 것은 아래 그림과 같습니다:
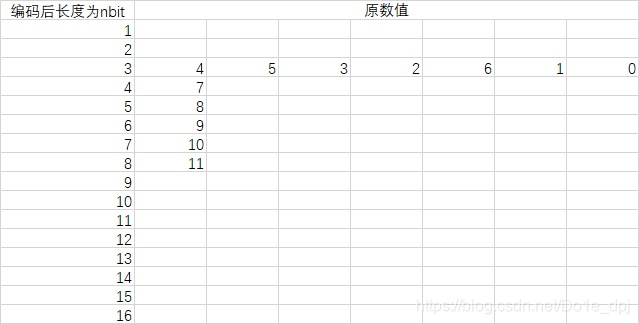
이제 우리는 각 원본 데이터가 인코딩된 후의 데이터 길이만 알고 있으며, 실제 값은 알지 못합니다.
표준 허프만 인코딩에는 자체 규칙이 있습니다:
- 가장 짧은 인코딩 길이의 첫 번째 숫자의 인코딩은 0입니다;
- 동일한 인코딩 길이의 인코딩은 연속적입니다;
- 다음 인코딩 길이(가정: j)의 첫 번째 숫자의 인코딩 a는 이전 인코딩 길이(가정: i)의 마지막 숫자의 인코딩 b에 따라 결정됩니다. 즉,
a=(b+1)<<(j-i)입니다.
규칙 1에 따라, 4의 인코딩은 000임을 알 수 있습니다. 규칙 2에 따라, 5의 인코딩은 001, 3의 인코딩은 010, 2의 인코딩은 011... 0의 인코딩은 110입니다. 규칙 3에 따라, 7의 인코딩은 1110, 8의 인코딩은 11110... 입니다.
CodeBlock Loading...
최종적으로 얻은 허프만 사전은 비교적 길며, 제 github 프로젝트에서 확인할 수 있습니다. 그 안의 규칙을 찾으면 write_num 함수에서 사전의 인덱스를 그렇게 구한 이유를 이해할 수 있을 것입니다.